publications
Some of the research endeavours I have contributed to.
2024
- MDPI Electronics
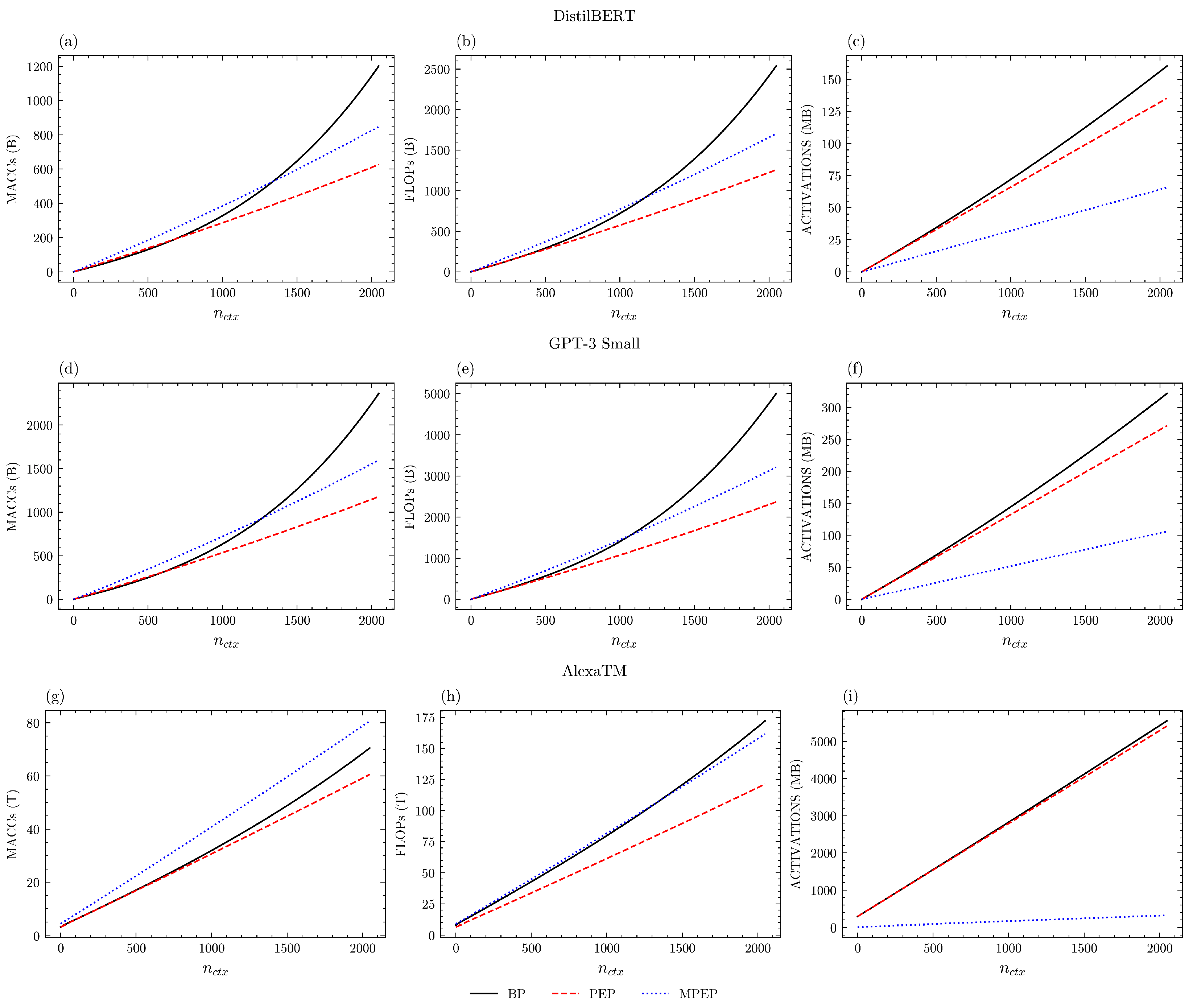 Forward Learning of Large Language Models by Consumer DevicesDP Pau, and FM AymoneMDPI Electronics, Jan 2024
Forward Learning of Large Language Models by Consumer DevicesDP Pau, and FM AymoneMDPI Electronics, Jan 2024Large Language Models achieve state of art performances on a broad variety of Natural Language Processing tasks. In the pervasive IoT era, their deployment on edge devices is more compelling than ever. However, their gigantic model footprint has hindered on-device learning applications which enable AI models to continuously learn and adapt to changes over time. Back-propagation, in use by the majority of deep learning frameworks, is computationally intensive and requires storing intermediate activations into memory to cope with the model’s weights update. Recently, “Forward-only algorithms” have been proposed since they are biologically plausible alternatives. By applying more “forward” passes, this class of algorithms can achieve memory reductions with respect to more naive forward-only approaches and by removing the need to store intermediate activations. This comes at the expense of increased computational complexity. This paper considered three Large Language Model: DistilBERT, GPT-3 Small and AlexaTM. It investigated quantitatively any improvements about memory usage and computational complexity brought by known approaches named PEPITA and MEMPEPITA with respect to backpropagation. For low number of tokens in context, and depending on the model, PEPITA increases marginally or reduces substantially arithmetic operations. On the other hand, for large number of tokens in context, PEPITA reduces computational complexity by 30% to 50%. MEMPEPITA increases PEPITA’s complexity by one third. About memory, PEPITA and backpropagation, require a comparable amount of memory to store activations, while MEMPEPITA reduces it by 50% to 94% with the benefits being more evident for architectures with a long sequence of blocks. In various real case scenarios, MEMPEPITA’s memory reduction was essential for meeting the tight memory requirements of 128 MB equipped edge consumer devices, which are commonly available as smartphone and industrial application multi processors.
@article{LLM, title = {Forward Learning of Large Language Models by Consumer Devices}, author = {Pau, DP and Aymone, FM}, journal = {MDPI Electronics}, volume = {13}, number = {2}, year = {2024}, month = jan, publisher = {MDPI}, doi = {10.3390/electronics13020402}, url = {https://www.mdpi.com/2079-9292/13/2/40}, }

2023
- IEEE COINS
 Suitability of Forward-Forward and PEPITA Learning to MLCommons-Tiny benchmarksDP Pau, and FM AymoneIEEE COINS, Jul 2023
Suitability of Forward-Forward and PEPITA Learning to MLCommons-Tiny benchmarksDP Pau, and FM AymoneIEEE COINS, Jul 2023On-device learning challenges the restricted memory and computation requirements imposed by its deployment on tiny devices. Current training algorithms are based on backpropagation which requires storing intermediate activations to compute the backward pass and to update the weights into the memory. Recently “Forward-only algorithms” have been proposed as biologically plausible alternatives to backpropagation. At the same time, they remove the need to store the intermediate activations which potentially lower the power consumption due to memory read and write operations, thus, opening to new opportunities for further savings. This paper investigates quantitatively the improvements in terms of complexity and memory usage brought by PEPITA and Forward-Forward computing approaches with respect to backpropagation on the MLCommons-Tiny benchmarks set as case studies. It was observed that the reduction in activations’ memory provided by “Forward-only algorithms” does not affect total RAM in Fully-connected networks. On the other hand, Convolutional neural networks benefit the most from such reduction due to lower parameters-activations ratio. In the context of the latter, a memory-efficient version of PEPITA reduces, on average, one third of the total RAM with respect to backpropagation, introducing only a third more complexity. Forward-Forward brings average memory reduction to 40%, and it involves additional computation at inference that, depending on the benchmarks studied, can be costly on micro-controllers.
@article{Suitability, title = {Suitability of Forward-Forward and PEPITA Learning to MLCommons-Tiny benchmarks}, author = {Pau, DP and Aymone, FM}, journal = {IEEE COINS}, volume = {}, issue = {}, year = {2023}, month = jul, publisher = {IEEE}, doi = {10.1109/COINS57856.2023.10189239}, url = {https://ieeexplore.ieee.org/abstract/document/10189239}, } - IEEE Sensors Letters
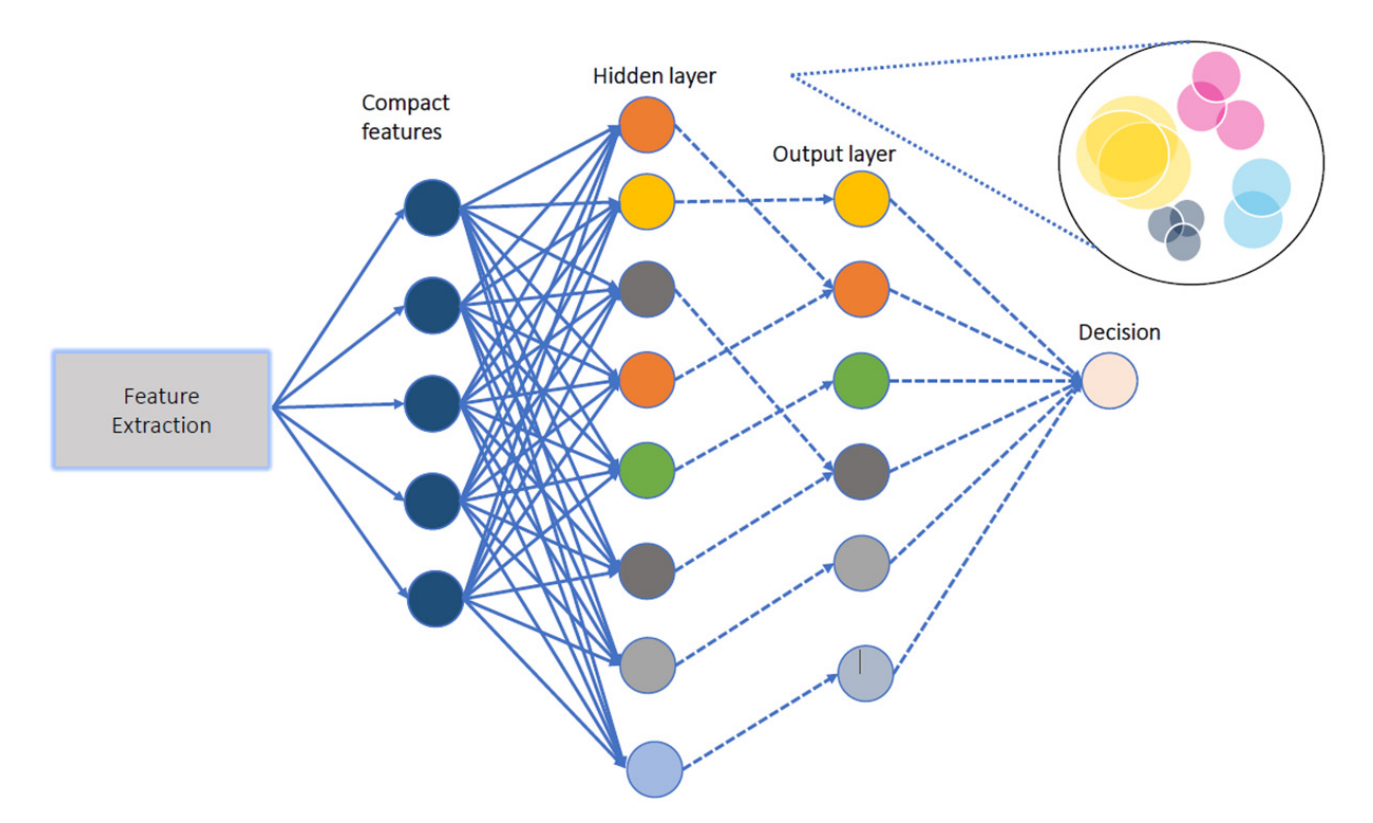 TinyRCE: Multipurpose Forward Learning for Resource Restricted DevicesDP Pau, A Pisani, FM Aymone, and 1 more authorIEEE Sensors Letters, Aug 2023
TinyRCE: Multipurpose Forward Learning for Resource Restricted DevicesDP Pau, A Pisani, FM Aymone, and 1 more authorIEEE Sensors Letters, Aug 2023The challenge of deploying neural network (NN) learning workloads on ultralow power tiny devices has recently attracted several machine learning researchers of the Tiny machine learning community. A typical on-device learning session processes real-time streams of data acquired by heterogeneous sensors. In such a context, this letter proposes Tiny Restricted Coulomb energy (TinyRCE), a forward-only learning approach based on a hyperspherical classifier, which can be deployed on microcontrollers and potentially integrated into the sensor package. TinyRCE is fed with compact features extracted by a convolutional neural network (CNN), which can be trained with backpropagation or it can be an extreme learning machine with randomly initialized weights. A forget mechanism has been introduced to discard useless neurons from the hidden layer, since they can become redundant over time. TinyRCE has been evaluated with a new interleaved learning and testing data protocol to mimic a typical forward on-tiny-device workload. It has been tested with the standard MLCommons Tiny datasets used for keyword spotting and image classification, and against the respective neural benchmarks. In total, 95.25% average accuracy was achieved over the former classes (versus 91.49%) and 87.17% over the latter classes (versus 100%, caused by overfitting). In terms of complexity, TinyRCE requires 22× less Multiply and ACCumulate (MACC) than SoftMax (with 36 epochs) on the former, whereas it requires 5× more MACC than SoftMax (with 500 epochs) for the latter. Classifier complexity and memory footprint are marginal w.r.t. the feature extractor, for training and inference workloads.
@article{TinyRCESens, title = {TinyRCE: Multipurpose Forward Learning for Resource Restricted Devices}, author = {Pau, DP and Pisani, A and Aymone, FM and Ferrari, G}, journal = {IEEE Sensors Letters}, volume = {7}, issue = {10}, year = {2023}, month = aug, publisher = {IEEE}, doi = {10.1109/LSENS.2023.3307119}, url = {https://ieeexplore.ieee.org/abstract/document/10225676}, } - MDPI Chips
 A Quantitative Review of Automated Neural Search and On-Device Learning for Tiny DevicesDP Pau, PK Ambrose, and FM AymoneMDPI Chips, May 2023
A Quantitative Review of Automated Neural Search and On-Device Learning for Tiny DevicesDP Pau, PK Ambrose, and FM AymoneMDPI Chips, May 2023This paper presents a state-of-the-art review of different approaches for Neural Architecture Search targeting resource-constrained devices such as microcontrollers, as well as the implementations of on-device learning techniques for them. Approaches such as MCUNet have been able to drive the design of tiny neural architectures with low memory and computational requirements which can be deployed effectively on microcontrollers. Regarding on-device learning, there are various solutions that have addressed concept drift and have coped with the accuracy drop in real-time data depending on the task targeted, and these rely on a variety of learning methods. For computer vision, MCUNetV3 uses backpropagation and represents a state-of-the-art solution. The Restricted Coulomb Energy Neural Network is a promising method for learning with an extremely low memory footprint and computational complexity, which should be considered for future investigations.
@article{AQuantitativeReview, title = {A Quantitative Review of Automated Neural Search and On-Device Learning for Tiny Devices}, author = {Pau, DP and Ambrose, PK and Aymone, FM}, journal = {MDPI Chips}, volume = {2}, issue = {2}, year = {2023}, month = may, publisher = {MDPI}, doi = {10.3390/chips2020008}, url = {https://www.mdpi.com/2674-0729/2/2/8}, } - IEEE MetroXRAINE
 TinyRCE: Forward Learning Under Tiny ConstraintsDP Pau, PK Ambrose, A Pisani, and 1 more author2023 IEEE International Conference on Metrology for eXtended Reality, Artificial Intelligence and Neural Engineering (MetroXRAINE), Oct 2023
TinyRCE: Forward Learning Under Tiny ConstraintsDP Pau, PK Ambrose, A Pisani, and 1 more author2023 IEEE International Conference on Metrology for eXtended Reality, Artificial Intelligence and Neural Engineering (MetroXRAINE), Oct 2023The challenge posed by on-tiny-devices learning targeting ultra-low power devices has recently attracted several machine learning researchers. A typical on-device model learning session processes real time streams of data produced by heterogeneous sensors. In such a context, this paper proposes TinyRCE, a forward-only learning approach based on a hyperspherical classifier aiming to be deployed on microcontrollers and, potentially, on sensors. The learning process is fed by labeled data streams to be classified by the proposed method. The classical RCE algorithm has been modified by adding a forget mechanism to discard useless neurons from the classifier’s hidden layer, since they could become redundant over time. TinyRCE is fed with compact features extracted by a convolutional neural network which could be an extreme learning machine. In such case, the weights of the topology were randomly initialized instead of trained offline with backpropagation. Its weights are stored in a tiny read-only memory of 76.45KiB. The classifier required up to 40.26KiB of RAM to perform a complete on-device learning workload in 0.216s, running on an MCU clocked at 480MHz. TinyRCE has been evaluated with a new interleaved learning and testing protocol to mimic an on-tiny-device forward learning workload. It has been tested with openly available datasets representing human activity monitoring (PAMAP2, SHL) and ball-bearing anomaly detection (CWRU) case studies. Experiments have shown that TinyRCE performed competitively against a supervised convolutional topology followed by a SoftMax classifier trained with backpropagation on all these datasets.
@article{TinyRCEMetroXRAINE, title = {TinyRCE: Forward Learning Under Tiny Constraints}, author = {Pau, DP and Ambrose, PK and Pisani, A and Aymone, FM}, journal = {2023 IEEE International Conference on Metrology for eXtended Reality, Artificial Intelligence and Neural Engineering (MetroXRAINE)}, volume = {}, issue = {}, pages = {295-300}, year = {2023}, month = oct, publisher = {IEEE}, doi = {10.1109/MetroXRAINE58569.2023.10405784}, url = {https://ieeexplore.ieee.org/document/10405784}, } - MDPI ENG
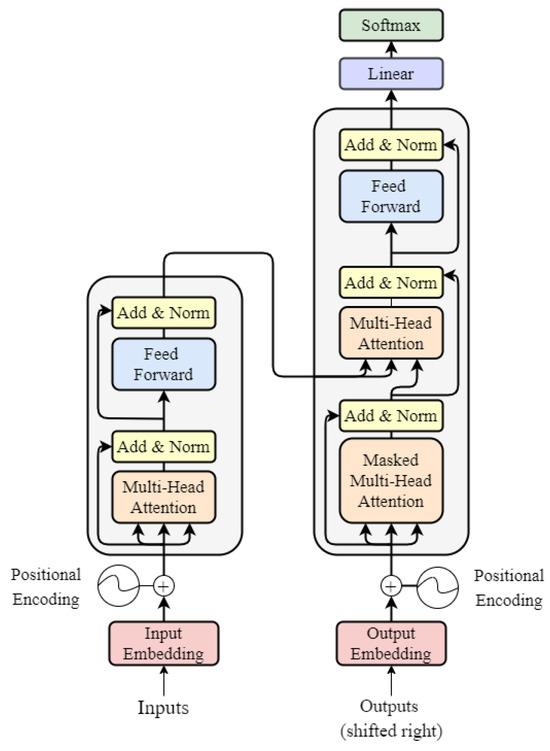 Mathematical Formulation of Learning and Its Computational Complexity for Transformers’ LayersDP Pau, and FM AymoneMDPI ENG, Dec 2023
Mathematical Formulation of Learning and Its Computational Complexity for Transformers’ LayersDP Pau, and FM AymoneMDPI ENG, Dec 2023Transformers are the cornerstone of natural language processing and other much more complicated sequential modelling tasks. The training of these models, however, requires an enormous number of computations, with substantial economic and environmental impacts. An accurate estimation of the computational complexity of training would allow us to be aware in advance about the associated latency and energy consumption. Furthermore, with the advent of forward learning workloads, an estimation of the computational complexity of such neural network topologies is required in order to reliably compare backpropagation with these advanced learning procedures. This work describes a mathematical approach, independent from the deployment on a specific target, for estimating the complexity of training a transformer model. Hence, the equations used during backpropagation and forward learning algorithms are derived for each layer and their complexity is expressed in the form of MACCs and FLOPs. By adding all of these together accordingly to their embodiment into a complete topology and the learning rule taken into account, the total complexity of the desired transformer workload can be estimated.
@article{TransformerMath, title = {Mathematical Formulation of Learning and Its Computational Complexity for Transformers’ Layers}, author = {Pau, DP and Aymone, FM}, journal = {MDPI ENG}, volume = {5}, number = {1}, pages = {34--50}, year = {2023}, month = dec, publisher = {MDPI}, doi = {10.3390/eng5010003}, url = {https://www.mdpi.com/2673-4117/5/1/3}, } - MDPI Electronics
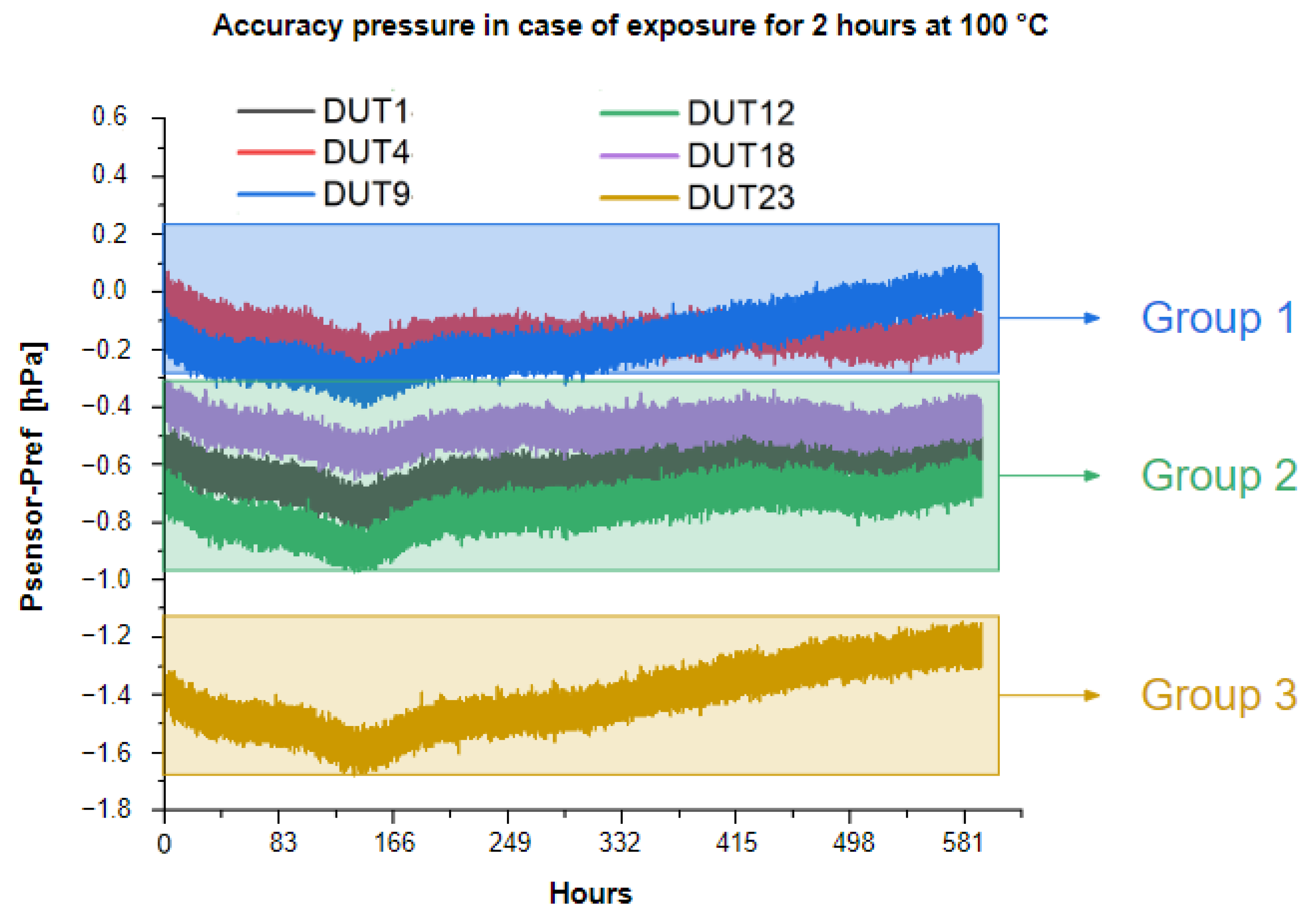 Tiny Machine Learning Zoo for Long-Term Compensation of Pressure Sensor DriftsDP Pau, W Ben Yahmed, FM Aymone, and 2 more authorsMDPI Electronics, Nov 2023
Tiny Machine Learning Zoo for Long-Term Compensation of Pressure Sensor DriftsDP Pau, W Ben Yahmed, FM Aymone, and 2 more authorsMDPI Electronics, Nov 2023Pressure sensors embodied in very tiny packages are deployed in a wide range of advanced applications. Examples of applications range from industrial to altitude location services. They are also becoming increasingly pervasive in many other application fields, ranging from industrial to military to consumer. However, the inexpensive manufacturing technology of these sensors is strongly affected by environmental stresses, which ultimately affect their measurement accuracy in the form of variations in gain, hysteresis, and nonlinear responses. Thermal stresses are the main source of sensor behavior deviation. They are particularly insidious because even a few minutes of high temperature exposure can cause measurement drift for many days in the sensor responses. Therefore, conventional calibration techniques are challenged in their adequacy to achieve high accuracy and over the entire deployment life of the sensor. To manage this, several costly and time-consuming calibration procedures have to be performed. Machine learning (ML) techniques are known, supported by the universal approximation theorem, to provide effective data-driven solutions to the above problems. In this context, this paper addresses two case studies, corresponding to post-soldering thermal stresses and exposure to moderately high temperatures, for which two separate datasets have been built and 53 different tiny ML models (collected into a zoo) have been devised and compared. The ML zoo has been constructed with models such as artificial neural networks (ANN), random forest (RFR), and support vector regressors (SVR), able to predict the error introduced by the thermal drift and to compensate for the drift of the measurements. The models in the zoo also satisfy the memory, computational, and accuracy constraints associated with their deployment on resource-constrained embedded devices to be integrated at the edge. Quantitative results achieved by the zoo are reported and discussed, as well as their deployability on tiny micro-controllers. These results reveal the suitability of a tiny ML zoo for the long-term compensation of MEMS pressure sensors affected by drift in their measurements.
@article{PressSens, title = {Tiny Machine Learning Zoo for Long-Term Compensation of Pressure Sensor Drifts}, author = {Pau, DP and Ben Yahmed, W and Aymone, FM and Licciardo, GD and Vitolo, P}, journal = {MDPI Electronics}, volume = {12}, number = {23}, year = {2023}, month = nov, publisher = {MDPI}, doi = {10.3390/electronics12234819}, url = {https://www.mdpi.com/2079-9292/12/23/4819}, }





